OUTPUT IMAGES
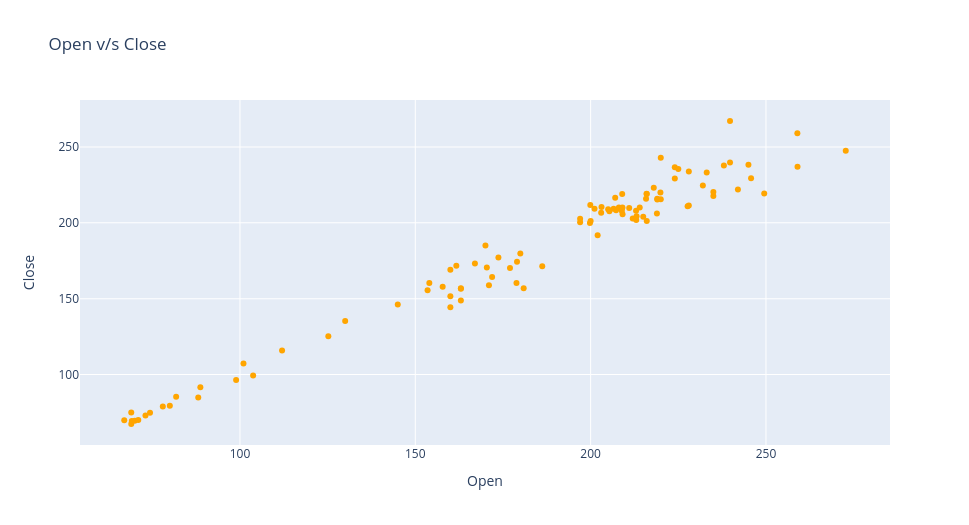
Data Visualization Open Vs Close
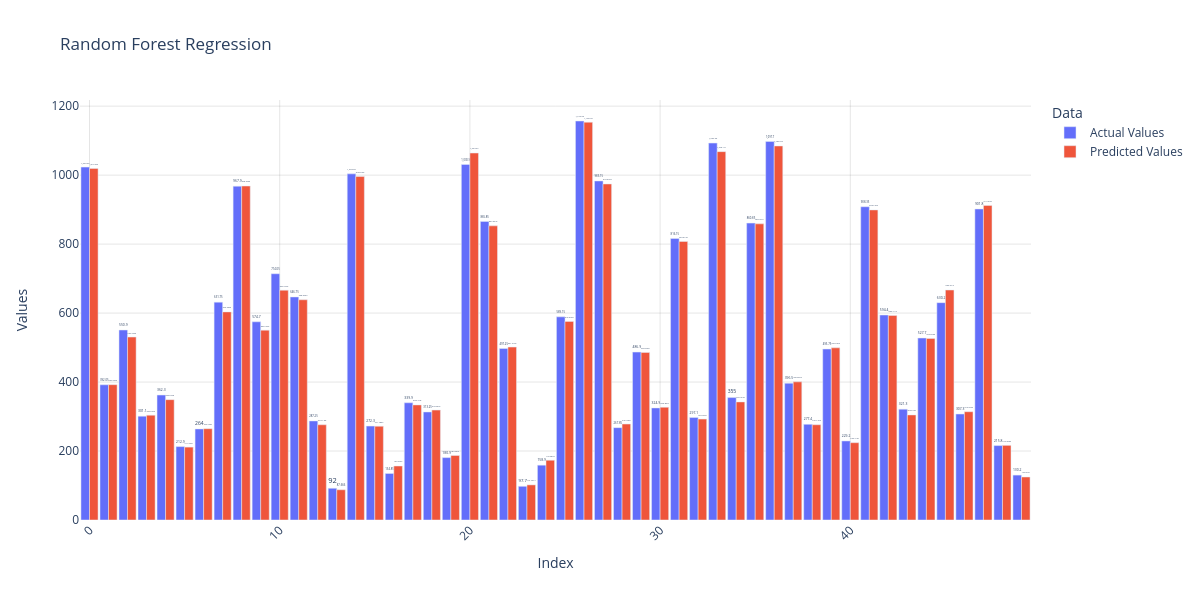
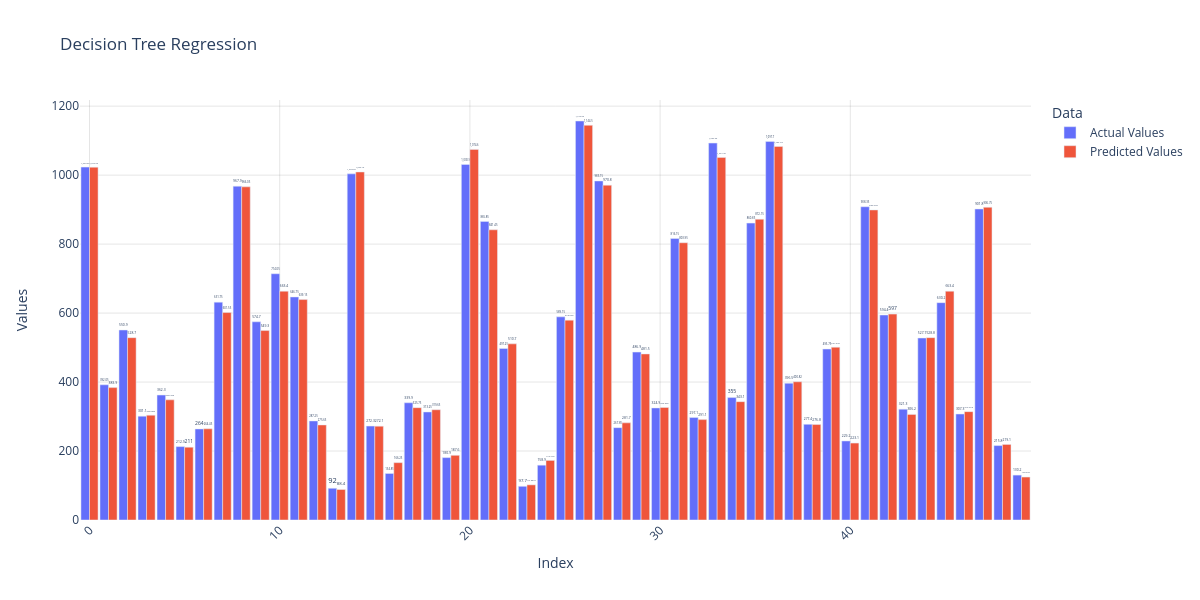
Decision Tree Regression
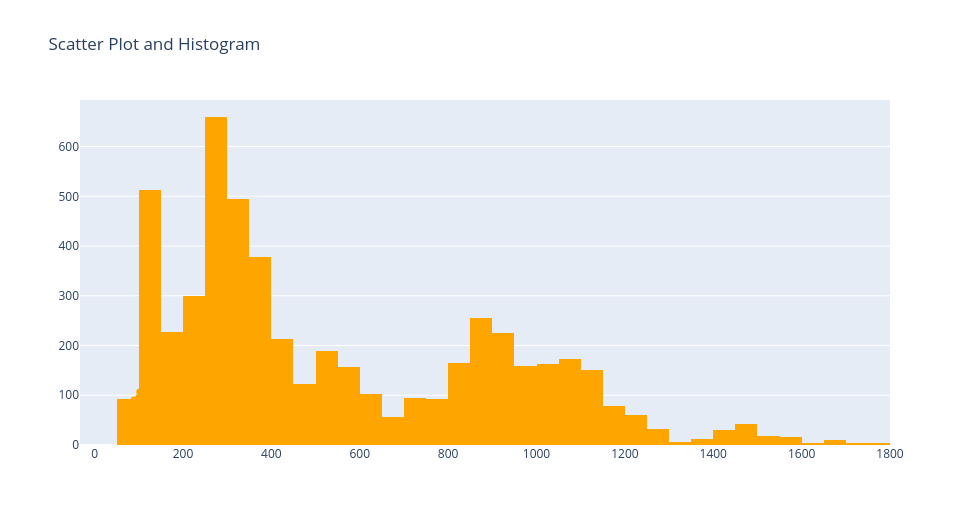
Scatter Plot and Histogram
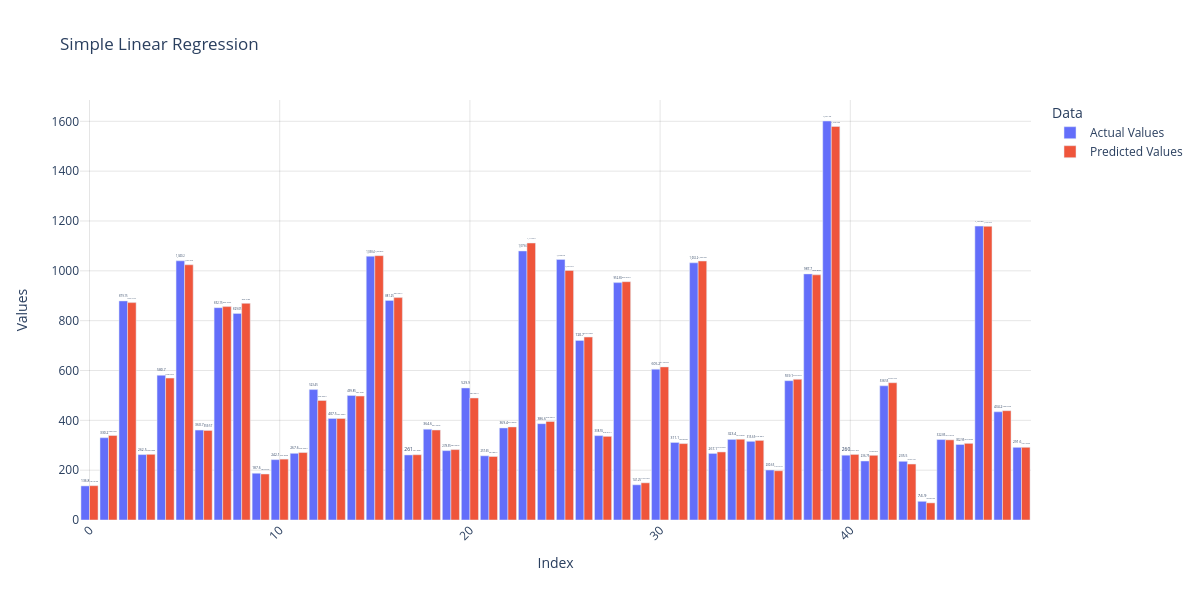
Simple Linear Regression
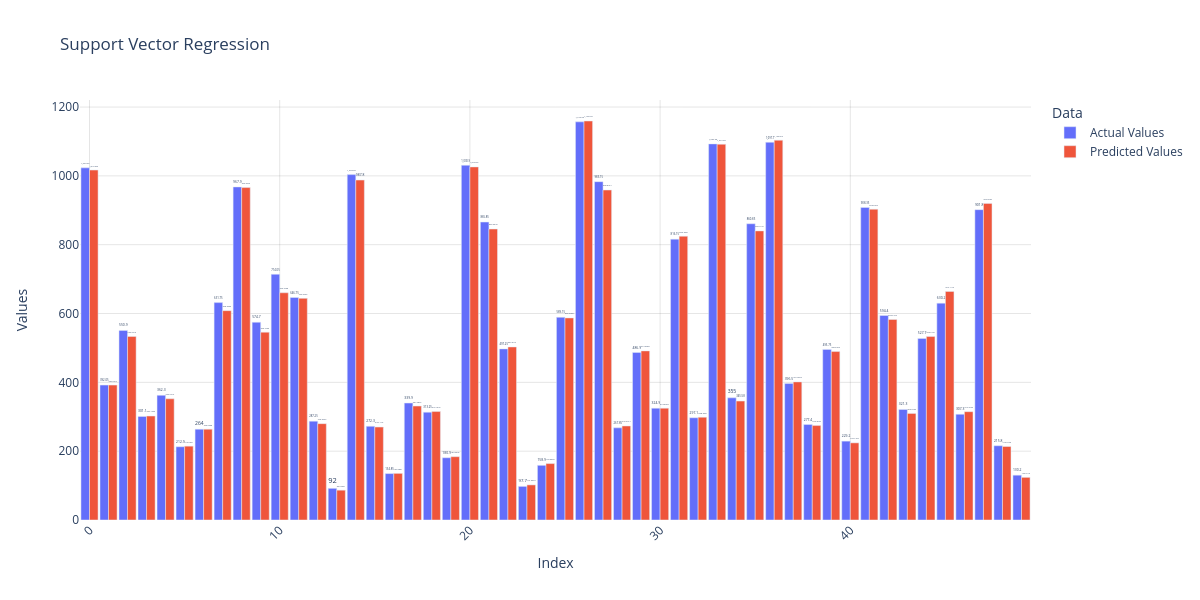
Support Vector Regression
Support Vector Regression
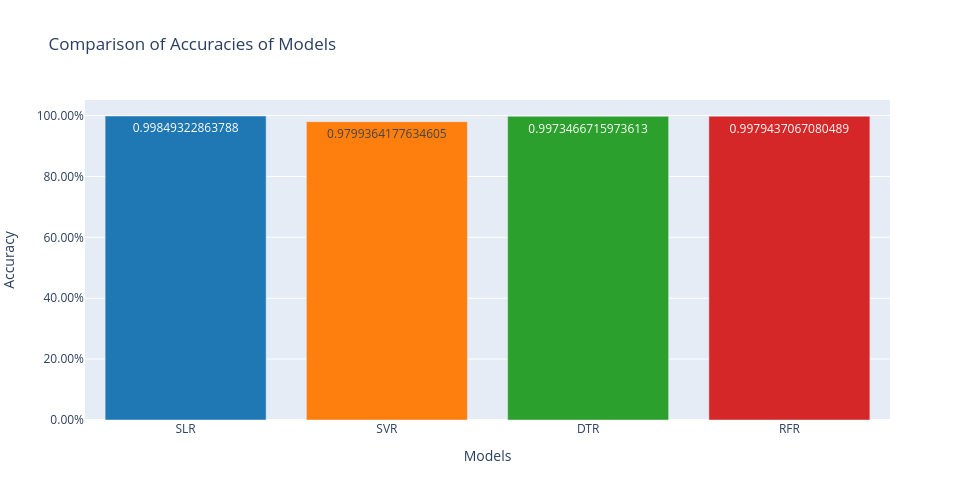
Comparison Of Accuracies Of Models
In [348]:
fig, ax = plt.subplots()
ax.axis('off')
props = dict(boxstyle='round', facecolor='lightblue', alpha=0.5)
ax.text(0.5, 0.5, 'THANK YOU', va='center', ha='center', fontsize=30, fontweight='bold', bbox=props)
plt.show()
